网站防刷点赞实战指南:搭建系统+保障数据真实
拥有网站的站长最为头疼的就是互动数据存在虚假内容, 这个虚假像是被水掺和了, 点赞的数量看上去是挺高的, 然而全部都是借助机器刷出来的, 这不但会对用户信任产生影响, 而且还会把运营决策误导了, 如若要去解决这个问题 其核心之处是在于构建一套能够进行识别并且可以拦截刷量行为的防刷系统。
如何识别刷赞行为
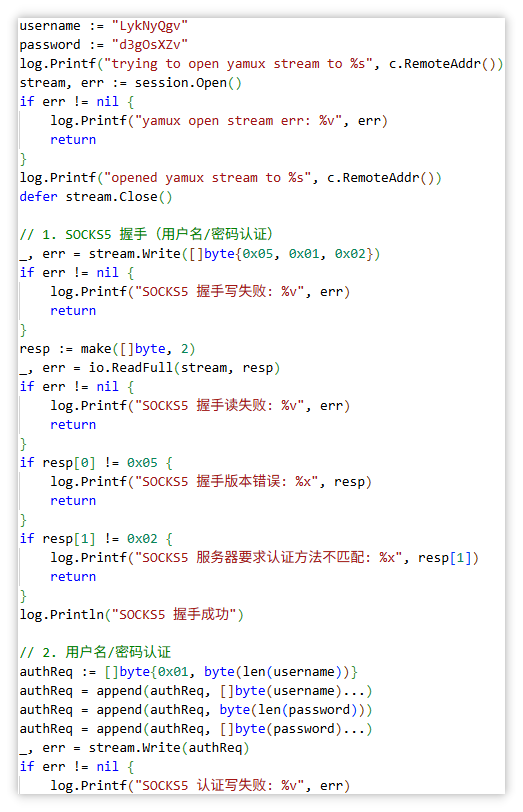
本质而言, 刷赞是系统于短期间之类收到了大量源起异常设备的请求。最为常见的识别法子是限定IP频率。比如说, 设定一个IP在1分钟里最多能够进行5次点赞操作。在代码的层面上, 可以借助Redis来记录IP的请求次数。如下是一段Python示例, 它借助Flask以及Redis达成了IP频率的限制:
import redis
from functools import wraps
from flask import request, jsonify
r = redis.Redis(host='localhost', port=6379, db=0)
def rate_limit(limit=5, period=60):
def decorator(f):
@wraps(f)
def wrapper(args, kwargs):
ip = request.remote_addr
key = f"like:{ip}"
count = r.get(key)
if count is None:
r.setex(key, period, 1)
elif int(count) >= limit:
return jsonify({"code": 429, "msg": "点赞过于频繁"}), 429
else:
r.incr(key)
return f(args, kwargs)
return wrapper
return decorator这段代码会对超出频率的请求予以拦截, 把429状态码返回。然而仅仅依靠IP进行限流是不行的, 原因是刷手能够变换IP。另外还得添加用户行为特征分析, 比如说鼠标轨迹、页面停留的时间、请求间隔是不是均匀这类。正常的用户在点赞之前会存在几秒的阅读行为, 不过脚本刷赞的请求间隔基本上是完全一样的。
防刷系统搭建的关键点
从事搭建完备的防刷系统工作, 这需要前端与后端相互协作配合。前端这边要去采集行为方面的数据, 像是用户位于页面之上的滚动深度情况, 还有点击事件得以触发的位置所在处, 亦或是页面焦点发生改变的相关状况。这些所获取的数据能够在经过加密处理之后借由接口传递给后端, 而后端利用规则引擎与否或者机器学习模型来判别究竟是真人还是机器。
后端提议采用多层校验机制, 第一层是签名验证之时, 每个点赞请求会附带一个由前端所生成的动态Token, 此Token涵盖时间戳以及随机数, 而后端解密之后要检查时间戳是不是处于有效期内, 第二层是设备指纹之处, 借由Canvas渲染、WebGL等这类信息生成唯一设备ID, 针对频繁出现的相同设备ID予以封禁, 第三层是关联分析之际, 要是多个设备ID同时点赞, 而且IP段相近, 极有可能是利用代理池刷量,直接清空这些点赞并且加入黑名单。
部署实际状况下, 能够借助Nginx协同Lua脚本构建首道防线, 针对高频IP径直予以拒绝。后端运用Redis或者Memcached实施缓存, 防止每次限流之际都去查询数据库。要是流量庞大, 提议引入消息队列, 点赞请求率先进入队列, 异步开展处理校验, 如此一来即便存在瞬时高峰也不至于使服务器不堪重负。
一旦防刷系统搭建完毕, 必然得开展压力测试。借助Apache JMeter去模拟出高并发点赞的情况, 进而观察系统有无异常, 查看限流是否发挥效用。除此之外, 要定时去更新规则库, 由于刷量技术也处在不断进化当中, 就像存有部分能够模仿人类行为的刷手, 经由随机延迟1到3秒之后才发出请求。在这个时候便需要引入更为复杂的算法了, 诸如隐马尔可夫模型这般去检测行为模式是不是自然。
否玩代码编辑 https://www.fouwan.com